Machine learning methodologies, particularly neural networks, are computer algorithms inspired by the structure and function of the human brain. These algorithms are capable of learning from data, identifying patterns, and making predictions or decisions without being explicitly programmed. Neural networks consist of interconnected nodes organized into layers, including input, hidden, and output layers (see figure below). During training, they adjust the strength of connections between nodes, called weights, based on examples from a dataset, allowing them to learn complex patterns and relationships in the data. Neural networks are widely used in various applications, including image recognition, natural language processing, and climate modeling.
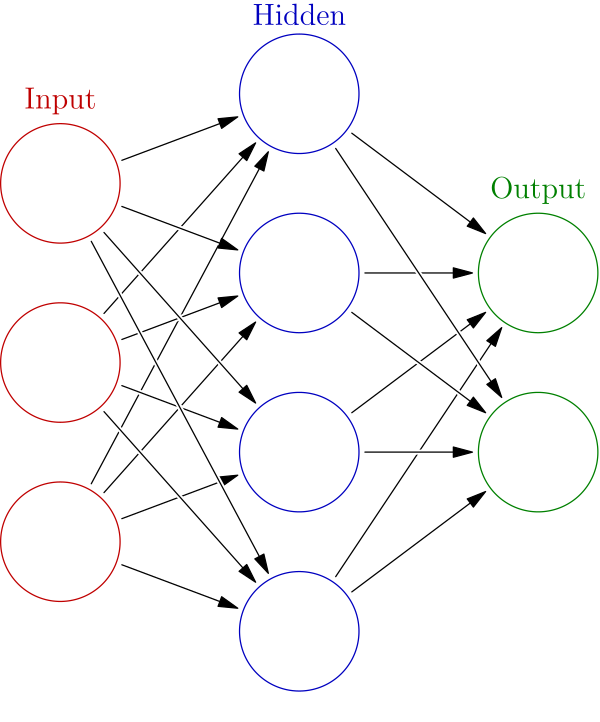
Source: wikipedia
Machine learning for climate modeling
Climate models often face challenges in representing complex processes and managing the computational demands of large-scale simulations. Machine learning presents innovative approaches to confront these obstacles. It provides new methodologies to learn missing model physics and model errors directly from data. Moreover, machine learning holds the potential to act as a feasible substitute for emulating the complete dynamics of models, thus offering an alternative to traditional climate modeling approaches. The next three paragraphs describe three applications of machine learning for climate modeling that are pursued within the M²LInES project.
Learning missing physics (“parameterization learning”)
One of the key applications of machine learning in climate modeling is in parameterization learning. Parameterizations are used in climate models to represent subgrid-scale processes that are unresolved at the model’s grid scale. Machine learning algorithms can be trained on high-resolution simulations to learn these parameterizations directly from data, enabling more accurate representation of complex physical processes such as clouds, precipitation, and turbulence.
There are various approaches considered in M²LInES to learn parameterizations of ocean mesoscale eddies.
The data used to generate training data for mesoscale parameterizations includes idealized simulations in MOM6 ocean model (in projects of Everard and Balwada), idealized simulations in MITgcm ocean model (Zanna & Bolton 2020), idealized simulations in two-layer QG ocean model (Ross et al.. 2023, Perezhogin, Zanna & Fernandez-Granda 2023) and coupled climate models (Guillaumin & Zanna 2021, in a new project of Perezhogin).
Multiple approaches to represent parameterization, as a function of input coarse-grained variables, are considered. These include equation-discovery models (Zanna & Bolton 2020, Perezhogin et al., 2024), small local fully connected neural networks (in three projects of Perezhogin, Everard, and Balwada), convolutional neural networks (CNN, Guillaumin & Zanna 2021, Zhang et al., 2023, Zhang et al., 2024), and generative models (Perezhogin, Zanna & Fernandez-Granda 2023).
In terms of parameterized physics there is also a difference. In works of Ross et al., 2023 and Perezhogin, Zanna, Fernandez-Granda 2023, both momentum and buoyancy subgrid forcings are combined into a potential vorticity forcing. In Perezhogin et al., 2024, the momentum fluxes are parameterized. In a project of Balwada, buoyancy subgrid forcing is parameterized. Finally, in a project of Everard, buoyancy and momentum effects are combined into a single parameterization using the Eliassen-Palm flux and thickness-weighted averaging.
Five parameterizations (equation discovery, neural networks of Perezhogin, Everard and Balwada, and CNN) are implemented and tested in ocean model MOM6 in various configurations: idealized Double Gyre and NeverWorld2 and realistic global ocean model OM4 at eddy-permitting resolution (¼-degree). Improvement in representation of the kinetic and available potential energy, and the mean flow was shown in idealized configurations (Perezhogin et al., 2024). In the global ocean model, the mesoscale parameterization reduces local biases such as North Atlantic cold bias, and enhances the systematic effect of mesoscale eddies such as northward heat transport and ocean restratification (i.e. interior cooling).
Learning model error
Machine learning algorithms can also be used to understand and correct biases that are due to the combined error of physics and numerics. One way to learn this combined error is to use analysis increments as a training dataset. Analysis increments represent the adjustments made to a model to bring it closer to observations during the data assimilation process. The information contained in analysis increments allows therefore for the development of correction schemes that improve the reliability and accuracy of model predictions.
Emulation of the full model dynamics
Another important application of machine learning in climate modeling is the development of emulators. Climate model emulators are surrogate models that mimic the behavior of complex climate models. These emulators are trained on data generated by climate models to approximate their responses to different inputs. By capturing the essential features and relationships within the original models, emulators provide a computationally efficient alternative for exploring climate model outputs. Samudra (Dheeshjith et al., 2024) is a global ocean emulator that is skillful at emulating the contemporary ocean, building on our earlier regional surface emulators for climate change (e.g., Subel and Zanna, 2024; Dheeshjith et al.., 2024). Without further modification, Samudra could be used in studies requiring large ensembles (e.g., extreme events) or to enhance and accelerate operational applications (e.g., data assimilation). Samudra is more than a proof of concept for affordable emulation of expensive ocean circulation models and could be used off-the-shelf for many applications. It will allow us to accelerate climate modeling and research.


