news
Joan Bruna - Neural Galerkin Scheme with Active Learning for High-Dimensional Evolution Equations
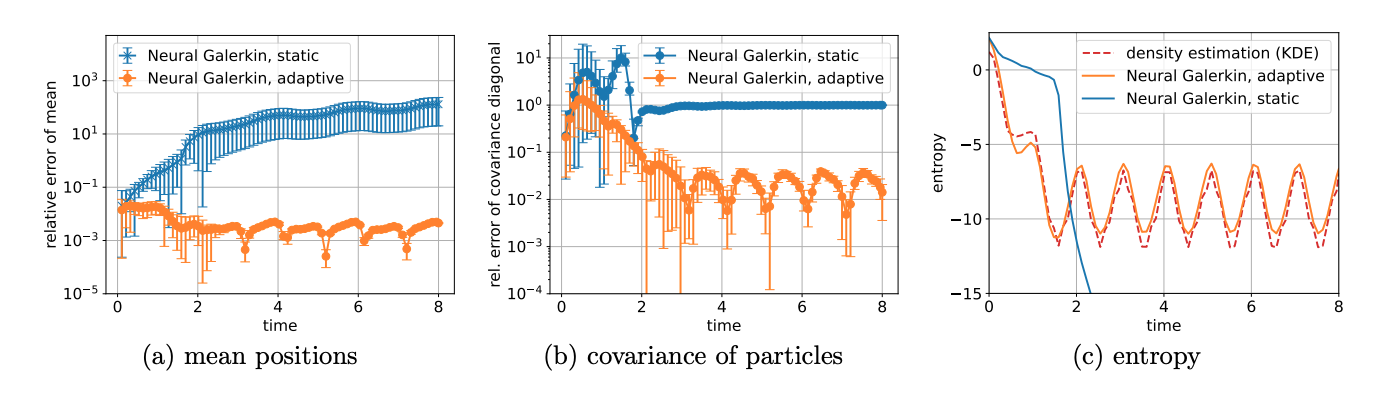
Lead author Joan Bruna introduces in this preprint , a method to use deep neural network when training data are initially unavailable: Neural Galerkin schemes integrate time-dependent partial differential equations with deep networks by generating the data needed to advance their solution on-the-fly using importance sampling.


